序
最近濒临毕业,在学校里一堆乱七八糟的事忙完后终于可以开始静下心来做毕设同时做些技术探究了。当在上篇文章中提到的内存模型的有关概念提给了毕设导师后立刻被打了下来,怎么说呢,虽然没有想象中的恐怖批斗,但还是被指出了一些问题(不急,接下来我会说明)。所以便开始了在网络上的胡乱遨游,终于找到了一个可以用来参考的成功对象:Unity,所以之后可能ShadowPlayEngine的系列会暂时搁浅一段时间,我会暂时将注意力放在对现有游戏引擎架构与API的探讨以及优秀架构的实现思路上,为ShadowPlay Engine打一个坚实的基础。毕竟盲目造轮子是不可取的。那么接下来我将会通过说明之前内存结构出现的问题来引出Unity的内存模型原理。
第一部分
需要承认一点,虽然之前的ShadowPlay的内存管理(这里仅指Release模式下的方案)方法设计本意是为了空间小且频繁的内存而准备的,但实话讲其实更加适配空间大且惰性较高的内存,为何这么说?我再把之前那张SPMemPool示意放出来:
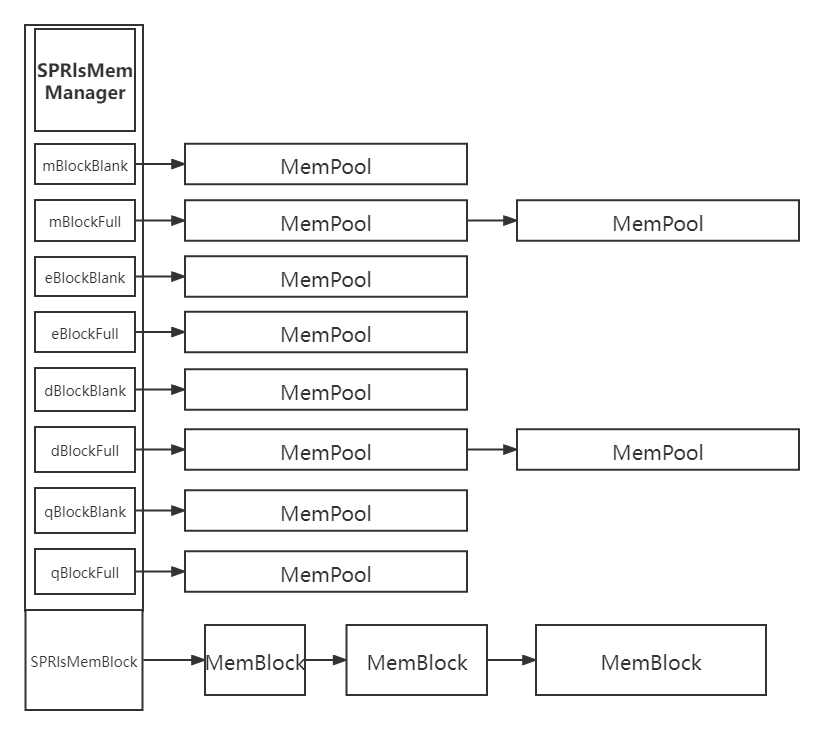
每一种块长的内存池均由两个指针管理:即“空(Blank)”和“满(Full)”。当一个MemPool对象满了之后就会立即将其从Blank指针转移到Full指针,如果此时Full中的池子不止一个,那么根据链表结构实现方式头插以及尾插会消耗一定的时间。再一个,反之如果有一个池子中的块空间被引擎“释放”掉(这里指引擎认为可以给后续新的请求分配这块空间),那么引擎会立即将其转移到Blank指针,如果这个块空间对应的池子位于Full指针管理的链表中间,那么遍历以及链表指针操作又会成为一大笔性能开销。
或许对于模型资源、材质资源、模型资源等可以通过享元模式达到重复使用的占用空间大且惰性较高的内存来说,以上方式是内存分配比较优秀的解法之一,但实际上对于小数据量且惰性极低的数据内存来说,还是不够快。
还有一个需要注意的问题,以上MemPool在设计之初并未考虑过内存块相关信息的存储能力,倒是在Debug模式下有相关信息的输出。但需要明确,不止游戏以及引擎开发人员需要内存块的相关信息,可能引擎内的某些系统也会需要。
最常见的一个例子就是引擎的反射系统,反射系统的基石就是数据类型,在目前一些比较成熟的反射框架中,其类型萃取系统中的一部分就是通过内存中存储信息来快速获取类对象实例的类型从而再由序列化系统进行序列化操作。以此为例,那么一个单一的内存块中就要包含数据类型、数组标识符、调试信息等一系列的内存块信息“头”。但MemPool在设计之初并未考虑到这些,而关于这些“头”如何在当前MemPool架构下快速且优雅的存储,这就又是一个令人头痛的问题了。
最后一个问题即是向操作系统申请内存的方法上,SPMemManager是直接通过malloc函数获取内存,当然用malloc获取内存空间并没有什么问题,毕竟unity都直接通过new以及malloc获取内存的,甚至都没用过virtual_alloc (Windows) 或者 _sbrk (Linux)。但问题出在了SPMemManager的设计上,在设计上,将new以及malloc的关系理解成了典型的“new就是带了构造的malloc”,这显然是错误的,new以及malloc在设计上就是两个不同的东西。根据具体需要应当考虑使用操作系统提供的内存申请接口。
第二部分
总结一下,目前SPRlsMemManager存在的问题可以归结如下:
- 速度不够快
- 包含信息不全
综合上述两点,其实又可以牵出两点问题:
- 内存池对内存块的分割有问题
- 针对不同性质的内存(惰性高或者低)需要使用不同分配策略,而非直接分配
好,那么让我们通过Unity的内存方案来解决以上问题:
1. 栈内存池
造成速度不够快的因素主要是内存池之间的指针操作以及遍历查找操作,那么我们取消掉链表,使用新的数据结构来存储它。让我们回归自然,直接回归到Linux内存的分配方式,即sbrk的栈分配方式:通过栈顶指针移动来为申请动作分配内存,那么我们的内存池就是一个典型的栈结构
由上图可见,内存池是一个线性的栈空间,由一个栈顶指针和指向这段内存的栈底指针共同管理,或者使用带索引的线性数组作为内存池的数据结构,栈底指针以及栈顶指针可以用索引值代替。
在一切的开始,需要先对内存池的大小以及内存块大小进行定义,通过之前讲过的CPU分页大小为4KB来看,所申请的内存池大小尽量为4KB的整数倍,内存块的大小可以以32字节或64字节为准。当然,这个大小是包含内存信息头的,所以真实情况内存块内可存储大小会稍小于以上定义。内存信息头内会包含一个重要信息:占用标记,用来表明这一块内存是否被占用,也是内存池内存“释放”的依据。
在上述标准定义完成后,接下来就是分配策略。当我们的内存请求确实需要从栈内存池进行分配,那么这时栈顶指针向上推一个内存块大小,把这一块内存的指针传递出去,同时将占用标记设置为“占用”即可。若是需要释放,只需将内存块的占用标记设置为“未占用”并把栈顶指针向下推一个内存块大小即可。
不过这其中有个问题:如果需要释放掉的内存目前位于栈内存栈顶指针与栈底指针之间该怎么办?
很简单,将其占用标记设置为“未占用”就行,其他什么操作都不用做。即使等下次内存请求到来时栈顶指针还未到达这个内存块,内存的分配与释放还和往常一样照常进行就行。所以这也就造成了一个问题:无意义内存占用,即本块内存没被占用但依旧无法分配的情况。不过不用担心,还记得前面说的吗,栈内存池是专门为惰性低且数据量小的内存数据。能到栈内存的那必是生命周期跨度很小的存在。当栈内存池的栈顶指针开始向下推时,如果遇到一连串的内存块均是无意义的占用,那么它会一直下推,直到找到已占用的内存块或下推到栈底指针为止。当然反之,如果内存池已满,那么内存分配会自动将新的分配请求交给更慢的内存分配策略或者直接拒绝分配抛异常。当然,这都是后话了。
这便是Unity栈内存池分配器的实现思路,在其内部规定里,这个栈内存分配策略所能获得的内存池大小有两种:
- 编辑器模式下主线程有16MB的栈内存池空间,每个work线程(可以理解为专门为游戏开发者准备的线程池内线程)有256KB的空间。
- 运行时模式下(或者说已经打包好的游戏)主线程根据设备情况有128KB至1MB多种选择,每个work线程有64KB的空间。
说来比较有意思的是,这里的内存池大小主要是以64KB为倍数进行划分,这和它主要面向的平台有比较大的关系:ARM架构很早便已使用16-64KB大小的CPU页面划分。而x86架构因为历史原因主流还是以4KB进行页面划分(所以从某种方面来说所谓12GB“超大”内存手机并不大,真实情况需要除以16(笑))。由于Unity主要面向Arm架构的移动平台,而且64同样也是4的整数倍,所以在PC以及游戏主机上也并没有太大问题。
2. 内存管理整体结构
Unity有两部分的内存管理,一部分是C++ native层的内存管理,另一部分是C#脚本的Managed层的内存管理(或者可以叫做GC)。在native层里面,内存管理这一大部分大致是如下结构:
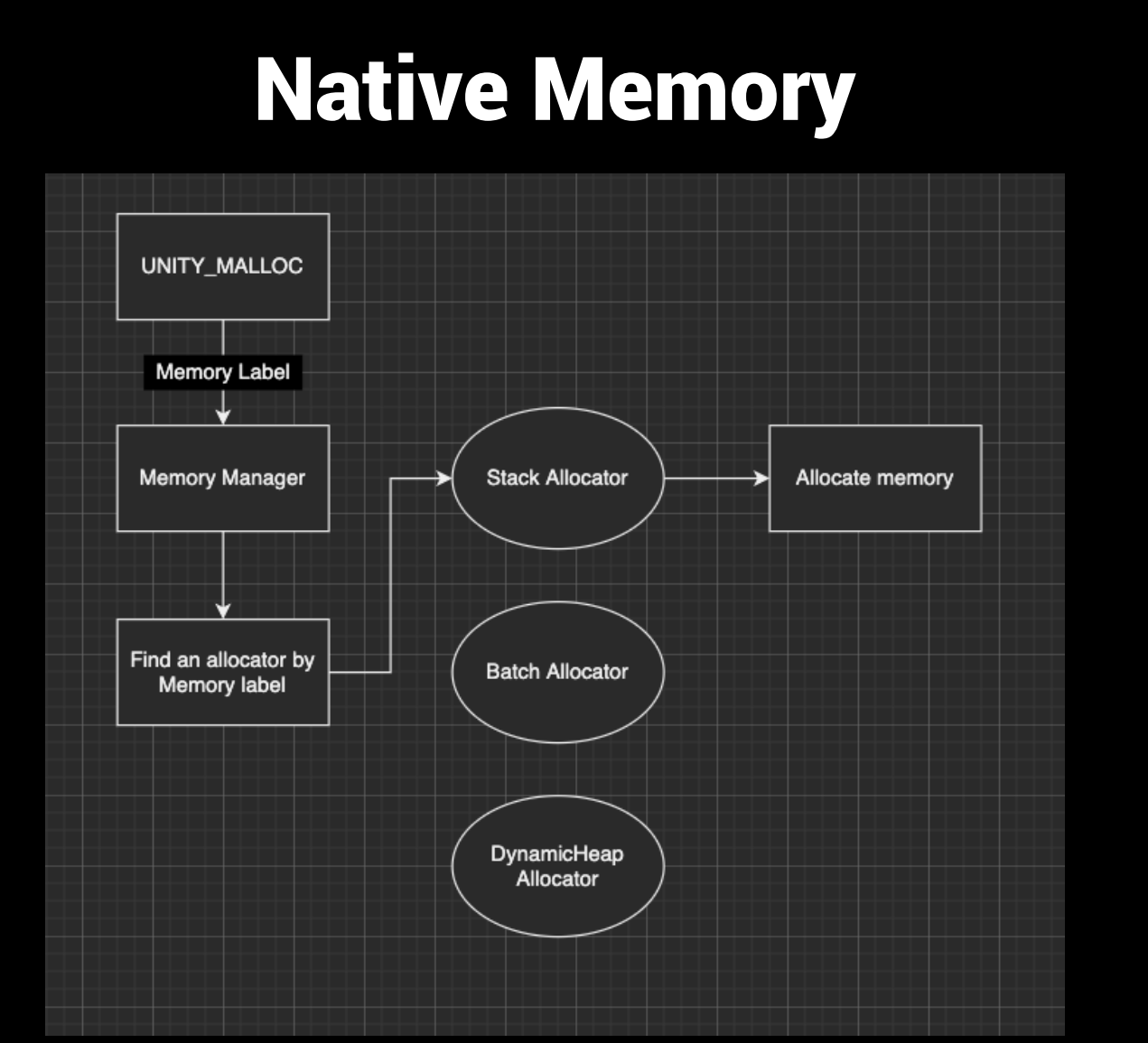
所有内存操作会通过一个Unity定义的宏UNITY_MALLOC去进行,并未通过重载new操作符。和SPMemManager不同,Unity并不会上来就为内存请求去分配。它会去为这个请求创建一个内存标签,这里面存储的大部分都是这个内存申请或释放操作发生的时间,位置,类型等消息,根据操作发生的位置以及大小等条件,比如是在Initialize(对应C#脚本里的awake或者start)还是Tick(对应C#脚本里的Update或者FixedUpdate)等来确定需要将这段内存通过哪种内存分配方式进行分配。然后再将请求提交给相对应的内存分配策略。
举一个比较简单的例子,现在有一个音频文件需要在游戏进行时进行播放。载入音频的后台向内存管理提出内存申请请求用来存储载入的音频文件,根据申请的发生位置(音频载入),可知这段内存的特性(大内存且内存惰性较高的资源文件)。所以调用BatchAllocator进行分配。同时,如果这段音效是某种转瞬即逝的特效音效而且在场景中大面积存在。那么根据享元模式,会创建很多这种特效代理对象。可知这种对象内存的特性(小内存且内存惰性极低的数据块)。所以调用StackAllocator进行分配(也就是上文说的栈内存分配)。当然这里只是在思想上与Unity一致,但是具体到分类方法、哪种资产资源用哪种分配策略以上只是大致进行说明,而非Unity实现方案。
结语
首先叠个甲,以上所讨论的unity内存模型只是在相关公开资料上整理并加入了我的个人理解后得来,所以并不能保证时效性,毕竟我一个学生娃子又没钱买得起Unity的源码服务。不过单论实现思路确实是非常值得参考的。毕竟闭门造车是不可取的嘛。
目前的话只是说明了一下Unity C++ Native 层的内存分配策略,而且也是仅限stack allocate。之后在研究了Managed部分的GC策略后会再进行详细的讨论。
引用
- Unity 2021 技术开放日

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行过许可