序言
之所以叫做CPlus语言,是因为原本是想起名为CMinus的,结果发现GitHub和Gitee上一堆的CMinus的编译器(想必都是开过编译原理课程并且写了个玩具级的语言编译器的大佬们吧)。但是CPlus相较于C多了一些东西,而相较于C++又少了一些东西,又有点C#的影子,而且并不严格遵守编译原理课本上的CMinus标准,所以暂且取个中间值,就叫C+(CPlus,反正目前还没人用,那我就抱走了)。
在开始之前,老规矩:
-
如果觉得这篇文章可以帮到你,欢迎一键三连(点赞,收藏,打赏(这一项只适用于在CSDN上))或者star和watch我的GitHub博客。
-
如果想要帮忙宣传一下,当然欢迎,不过还请转载标明出处。
-
我使用的C/C++ IDE是Microsoft Visual Studio 2017 Community(以下简称VS2017),WinSDK是10.0.17763.0。不过由于WinSDK造成的Bug在这种软件上并不致命。所以暂时忽略。
那么,好戏开场!(打响指)
1. 理论
在直接开始手撕CPlus的IDE之前,我们需要预先定义好CPlus的一些基础规则,当然,不是全部,因为在后面的话可能还是会像C++标准一样每隔一段时间就添加上那么亿点点细节。首先,说明一下CPlus和普通的C/C++有什么区别,这样或许更直观些:
-
CPlus支持面向对象编程,但不会像C++那样支持多继承,在这点上和目前主流的Java以及C#保持一致。当然,类与结构体中的成员有两种展现方式:public以及private。
-
关于比较恼人的指针问题,CPlus并不允许在基础数据类型(整型,浮点,布尔值等)上使用指针。但是,为了使CPlus更好的契合设计模式,允许在自定义结构体以及类类型里使用指针。而且在对象的生命周期结束后会自动回收(这一点有点儿难,不过这只是目前设想)。
-
稍微有点C/C++基础的各位都知道,在C++ 20标准之前,头文件一直是一个比较头疼的存在,尤其在VS上,加载速度慢以及 “LNK2019” 是常客,虽说前向声明可以解决不少问题,但还是有些力不从心(尤其是前向声明标准库的那些‘大爷们’)。CPlus吸取了C++ 20以及C#的包导入优点,使用import关键字作为外部导入关键字。
-
采用了多种长度的int类型:int8、int16、int32、int64以及相应的uint(无符号整型)。
接下来,就是定义CPlus里的关键字、运算符、界符、标识符相关的定义了,以便在编写词法分析器中起作用。
-
关键字: “int8”, “int16”, “int32”, “int64”, “uint8”, “uint16”, “uint32”, “uint64”, “float”, “double”, “bool”, “char”, “void”, “if”, “else”, “switch”, “case”, “break”, “continue”, “while”, “for”, “return”, “struct”, “class”, “public”, “private”, “import”, “true”, “false”, “default”
和C/C++没多大区别,少了#include以及#define等预处理器指令关键字,增加了import关键字。
-
运算符: “+”, “-“, “*”, “/”, “>”, “<”, “=”, “>=”, “<=”, “==”, “!”, “!=”, “&&”, “||”, “&”, “|”, “:”, “::”, “+=”, “.”, “,”
这没什么可说的
-
界符:” " “, “{“, “}”, “(“, “)”, “[”, “]”, “;”
-
数字:阿拉伯数字0 ~ 9,支持浮点数以及带正负号的数。
-
标识符:同C/C++一致,支持下划线作为标识符,同时支持字母与数字的组合作为标识符,但不允许以数字为开始字符。
-
注释:支持多行注释,但目前只支持” /**/ “注释符。
在上述这些基础定义完后,我们便可以开始定义词法分析器了,对于词法分析器的构建,我们可以用多种方法:使用现成辅助工具生成相关代码(著名的有JavaCC)、采用一大堆的if-else语句对读入的每个字符做一次判断、或者亲手构建一个符合CPlus词法的DFA。从方便性上来说,第一种方法是最不错的选择,但咱们是手撕,所以不做考虑。而且由于一大堆的if-else语句逻辑结构实在太过复杂,想用if-else实现树状结构实属愚蠢,所以,也就剩下最后一条路——构建符合CPlus词法的DFA。话不多说,先上图:
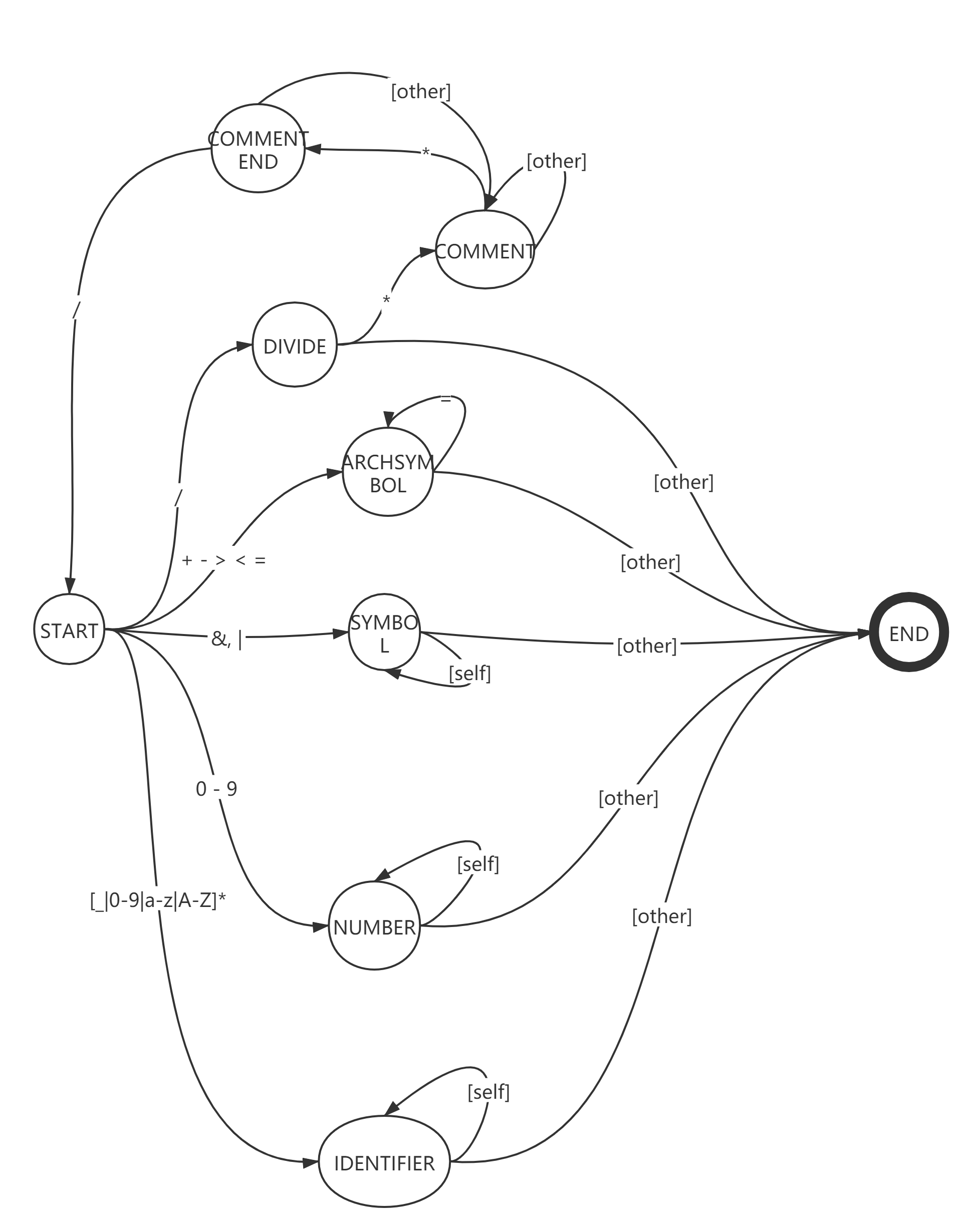
接下来开始解释:
所有的状态机都是一致的,均具备开始以及结束节点,还记得我在讲虚幻引擎AI系统的时候说过的行为树么?那也是一种状态机,同样具备开始和结束节点,只不过被隐藏掉了而已。虽说叫做状态机,但DFA全名为deterministic finite automata(确定状态的有穷自动机),实际上应该算是状态机的一个子集,虚幻引擎AI行为树也属于DFA,因为每种状态的触发都是有不同条件的,遵循着一对一原则。当DFA读入一个字符时,如果处于开始状态,那么会根据给出字符在ASCII对应的位置来锁定下一个应该到达的状态,以符号“斜线”为例,当DFA遇到读入字符为“斜线”时,会径直进入DIVIDE状态,在这时若状态机接受的下一个字符为星号时,那么便会进入COMMENT状态,若接收的是除星号以外的任意字符,那么便会将此“斜线”符号作为一个token保存起来,并以DIVIDE标记这个token,在以后的语法解析过程中当语法解析器遇到它后会说“啊,原来这是一个除号(DIVIDE)”。
当然,上图只是我为了解释DFA在真实计算机编程语言编译过程中词法解析的原理而画的一个简易的DFA,与真实的CPlus语言的DFA有一部分不一致的地方,有了基础的DFA思想以后,接下来就要开始手撕词法分析器部分了。当然,如何通过字符串流操作将文本代码存入内存的方法我就不再赘述,直接开始词法分析器部分。Talk is cheap and show me the code.
2. 词法分析器
2.1 DFA定义
在讲解虚幻引擎AI行为树时,我们用到了枚举类型来实现Agent的状态切换,枚举是个好东西,在代码层级上实现这一类的自动机也的确是要用到“enum + switch”来进行实现。(什么?构建网状数据结构来表示DFA?在C/C++里太麻烦了吧。你用的是JavaScript?哦那没事了。)
接下来展示一下DFA状态:
enum lexerDFAStatus
{
DFA_SLEEP,
DFA_START,
DFA_SYMBOL,
DFA_COMMENT,
DFA_NUM,
DFA_IDENTIFIER,
DFA_END
};
一共有七种:睡眠(DFA_SLEEP),开始(DFA_START),符号(DFA_SYMBOL),注释(DFA_COMMENT),数字(DFA_NUM),标识符(DFA_IDENTIFIER),结束(DFA_END)。
其中,睡眠指的是在词法分析器对象在构造函数里初始化状态机的时候用的,没什么特别的意义。开始和结束我不再过多说明,上面有提到。符号的话,就是在DFA遇到除52个大小写字母,0-9以及非法符号外的所有符号后跳跃到的状态。注释是指在DFA遇到了形如“/**/”的符号后进入的状态,此时在注释范围内的所有符号,DFA一概不读取。数字指在DFA遇到了0-9的数后进入的状态,当然在数字中间遇到了“.”也会将其归为数字范畴,毕竟是小数啊。标识符就是标识符,不解释。当然,在注释之外遇到了非法符号(比如‘……,¥,%,@,#’)会自动抛出异常并停止接下来的编译流程。
然后聪明又可爱的观众们就会问了,说:永乐,你为什么没有给关键字和标识符做区分呢?这其实不是什么问题,还请往后看。
2.2 token定义
本人计划使用单向链表来实现token对象的存储,相关定义如下:
/*
CPlus_CORE_API 可以无视掉,这是为了将tokenType开放出去,由于本编译器是以
dll动态链接库表现的,在使用时直接挂载即可,这也是为了考虑到IDE开发中
需要重复调用编译器的某项功能的情况(我总不可能把编译器和IDE写进一个项目里吧,耦合度可是很高的),
而封装成可运行二进制.exe文件时就没有这么自由了。关于dll的生成与调用,
敬请参阅我的《从新建文件夹开始构建UtopiaEngine(1)》文章,里面有详细介绍。
*/
enum CPlus_CORE_API tokenType
{
NOTHING,
KEYWORD,
SYMBOL,
DELIMITER,
NUMBER,
IDENTIFIER
};
struct lexerTokenData
{
tokenType tkt;
std::string value;
int rowLoc;
lexerTokenData() : tkt(NOTHING), value("Start node"), rowLoc(-1)
{
// Nothing.
}
void setToken(tokenType _tkt, std::string _value, int _rowLoc)
{
this->tkt = _tkt;
this->value = _value;
this->rowLoc = _rowLoc;
}
};
// This is struct for token Node.
struct lexerToken
{
lexerTokenData tokenSave;
lexerToken* nextNode;
lexerToken()
{
this->nextNode = nullptr;
}
};
tokenType指的是这则token所用的类型,有这么几种:NOTHING(啥也不是),KEYWORD(关键字),SYMBOL(合法符号),DELIMITER(界符),NUMBER(数字),IDENTIFIER(标识符)。和DFA状态定义一样,NOTHING只是为了方便构造函数初始化用的。
lexerTokenData是对要存储进token的数据做一个整合,其中存储了token的类型,token的值以及token所在的行数(话说行数这个东西在现在看来貌似没什么用,在以后的语法分析器中我会提及),lexerToken也就是存储token所用的链表结点的结构定义了。(什么?你还不知道结构体里可以写成员函数?敬请参阅C++ 11标准哦亲)
2.3 开始构建
必要的前置说明已经在上文中提过,直接上代码吧:
for (int i = 0; i < this->codeStr.size(); i++)
{
codeChar = this->codeStr[i];
if (this->DFA != DFA_COMMENT)
{
if ((codeChar >= '0') && (codeChar <= '9') && (this->DFA != DFA_NUM) && (this->DFA != DFA_IDENTIFIER)) { this->DFA = DFA_NUM; }
else if ((codeChar >= '0') && (codeChar <= '9') && (this->DFA == DFA_NUM));
else if ((codeChar >= '0') && (codeChar <= '9') && (this->DFA == DFA_IDENTIFIER));
else if ((codeChar >= 'a') && (codeChar <= 'z') && (this->DFA != DFA_IDENTIFIER) && (this->DFA == DFA_NUM))
{
ConsoleLog::PrintLog(COMPILER_LOG, CPCE_0003, CPCW_0000, "The identifier cannot start by number");
throw std::exception();
}
else if ((codeChar >= 'a') && (codeChar <= 'z') && ((this->DFA != DFA_IDENTIFIER))) { this->DFA = DFA_IDENTIFIER; }
else if ((codeChar >= 'A') && (codeChar <= 'Z') && (this->DFA != DFA_IDENTIFIER) && (this->DFA == DFA_NUM))
{
ConsoleLog::PrintLog(COMPILER_LOG, CPCE_0003, CPCW_0000, "The identifier cannot start by number");
throw std::exception();
}
else if ((codeChar >= 'A') && (codeChar <= 'Z') && ((this->DFA != DFA_IDENTIFIER))) { this->DFA = DFA_IDENTIFIER; }
else if ((codeChar >= 'a') && (codeChar <= 'z') && ((this->DFA == DFA_IDENTIFIER)));
else if ((codeChar >= 'A') && (codeChar <= 'Z') && ((this->DFA == DFA_IDENTIFIER)));
else if (codeChar == '_') { this->DFA = DFA_IDENTIFIER; }
else if ((codeChar == '/') && (this->codeStr[i + 1] == '*')) { this->DFA = DFA_COMMENT; }
else if ((codeChar == ' ') || (codeChar == '\n'))
{
switch (this->DFA)
{
case DFA_NUM:
this->tokenLLNodeAdd(NUMBER, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_END;
break;
case DFA_IDENTIFIER:
{
if (this->isKeyword(subCodeStr))
{
this->tokenLLNodeAdd(KEYWORD, subCodeStr, rowNum);
subCodeStr.clear();
}
else
{
this->tokenLLNodeAdd(IDENTIFIER, subCodeStr, rowNum);
subCodeStr.clear();
}
}
this->DFA = DFA_END;
break;
case DFA_COMMENT:
this->DFA = DFA_COMMENT;
break;
default:
break;
}
if (codeChar == '\n') { rowNum += 1; }
}
else if ((codeChar == '.') && (this->DFA == DFA_NUM));
else if (codeChar == '\t');
else
{
if (this->DFA == DFA_IDENTIFIER)
{
if (this->isKeyword(subCodeStr))
{
this->tokenLLNodeAdd(KEYWORD, subCodeStr, rowNum);
subCodeStr.clear();
}
else
{
this->tokenLLNodeAdd(IDENTIFIER, subCodeStr, rowNum);
subCodeStr.clear();
}
this->DFA = DFA_SYMBOL;
}
else if(this->DFA == DFA_NUM)
{
this->tokenLLNodeAdd(NUMBER, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_SYMBOL;
}
else if (this->DFA == DFA_COMMENT)
{
// Nothing.
}
else
{
this->DFA = DFA_SYMBOL;
}
}
}
else if (codeChar == '\n')
{
rowNum += 1;
}
switch (this->DFA)
{
case DFA_SYMBOL:
{
subCodeStr += codeChar;
if (this->isSymbol(subCodeStr))
{
subCodeStr += codeStr[i + 1];
if (this->isSymbol(subCodeStr))
{
i += 1;
this->tokenLLNodeAdd(SYMBOL, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_START;
}
else
{
subCodeStr.clear();
subCodeStr += codeChar;
this->tokenLLNodeAdd(SYMBOL, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_START;
}
}
else if (this->isDelimiter(subCodeStr))
{
this->tokenLLNodeAdd(DELIMITER, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_START;
}
else if (this->DFA != DFA_IDENTIFIER)
{
ConsoleLog::PrintLog(COMPILER_LOG, CPCE_0003, CPCW_0000, "You are use the unknown invalid symbol. This symbol is not supported at present.");
this->tokenLLDelete();
throw std::exception();
}
}
break;
case DFA_NUM:
subCodeStr += codeChar;
break;
case DFA_IDENTIFIER:
subCodeStr += codeChar;
break;
case DFA_COMMENT:
{
if ((codeChar == '*') && (this->codeStr[i + 1] == '/')) {
i += 1;
this->DFA = DFA_START;
}
}
break;
case DFA_END:
this->DFA = DFA_START;
break;
default:
break;
}
}
额,这的确有点多,一行行解释怕是各位也是听到了后面就忘了前面的,这样吧,我用几个实例带入进行说明,希望可以让各位理解。接下来会用到行号,还烦请各位将这段代码粘贴到NotePad++或者VSCode上方便阅读,在开始举例前,先对代码结构进行说明:
整个代码有一个外围大循环,主要是对每个读入的字符对号入座进行处理的。大循环里的步骤大致分为:分配状态(第4行至第24行) -> 保持状态加入子串(第98行至第155行) -> 打包token并分配token类型(凡是你能看到的this->tokenLLNodeAdd() 都是)。
好的,上实例:
-
我们先以关键字 “int8” 为例,此时DFA状态为DFA_START,当我们的读入指针codeChar到达了字符 “i” 时,DFA会先进入一个if判断,即判断当前DFA是否处在DFA_COMMENT状态,若是,那么跳至第93行进行接下来的处理,关于注释的处理我们稍后在讲。但此时状态并不是DFA_COMMENT,所以进行接下来的处理。根据要求会执行第14行的条件判断内的处理语句,将DFA状态设置为DFA_IDENTIFIER。完成后会跳至第98行进行状态判断,由于此时状态为DFA_IDENTIFIER,所以执行第140行语句,即向子串加入字符 “i” 。此时DFA会将DFA_IDENTIFIER状态保留并再次跳至大循环即从第3行再次读入下一个字符 “n” 。按照上面的逻辑循环若干次后来到了 “8” ,此时DFA的状态是DFA_IDENTIFIER,这时满足第8行要求,无状态转换语句,即保持原有状态。接下来进入第139行将“8”录入子串中,按照普通编程习惯以及语法规定,此时若要结束,必须要有一个空格或者换行符来隔开本标识符和下一个符号。假设是空格,此时DFA会转至第25行进行token录入操作。由于此时状态在DFA_IDENTIFIER中,则跳至第35行开始录入。在本文刚开始有一个问题即关于标识符和关键字的问题,这里便给出解决方法:由于子串中的 “int8” 属于关键字,则第37行判断返回结果为真,那么这个token便会被创建并被标识为 “KEYWORD(关键字)” ,DFA的状态也转换为DFA_END,在循环结束后回到DFA_START状态以便读取别的标识符以及别的文件内容。
-
接下来举一个关于注释的例子:“/* abcdefgh(这里有个换行符)+=*@#$%^ */”,在开始时,DFA状态为DFA_START,这时会进入第四行所在的条件判断内,接下来跳至第24行并将状态转换为DFA_COMMENT。此时会再次跳回循环开始处。若读取到换行符则会跳至第93行为行数加一,所以至少在CPlus语言中,向注释中加入 “\n” 形式的换行符且真实语义上并未换行的做法是非法的,只支持回车的隐式换行符。接下来若遇到了 “*” 以及 “/” 符号,则跳至第142行为序号i加1以跳过“/”符号。并将DFA状态切换为DFA_START,以准备下一阶段的读取。
3. 运行
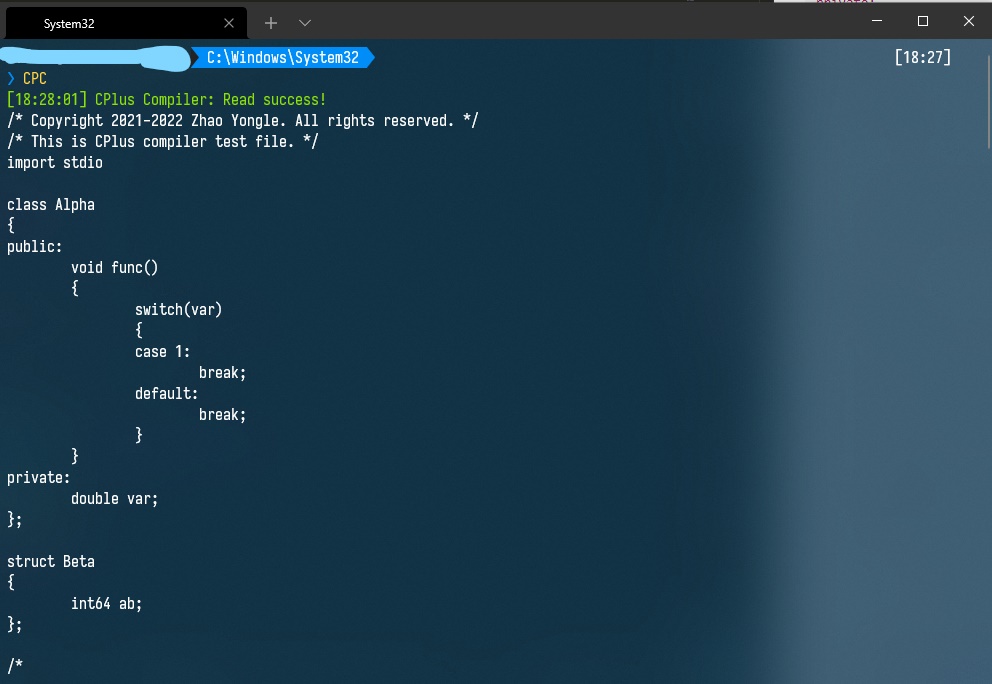
将项目生成的词法分析器用于解析下面的 .cpc(CPlus Code) 文件:
/* Copyright 2021-2022 Zhao Yongle. All rights reserved. */
/* This is CPlus compiler test file. */
import stdio
class Alpha
{
public:
void func()
{
switch(var)
{
case 1:
break;
default:
break;
}
}
private:
double var;
};
struct Beta
{
int64 ab;
};
/*
Multiline comment 1,
Multiline comment 2,
Multiline comment 3.
*/
int8 main()
{
if(true)
{
print("Hello, world!");
}
else if(false)
{
/* Nothing */
}
else {}
while(true)
{
/* Code+-*= */
}
for(int8 i = 0; i < 8; i++)
{
/* Loop body */
}
int32 _a = 32;
float b = -1.0+1.23456789;
bool c0 = false;
Alpha d;
d.func();
d.var;
return 0;
}
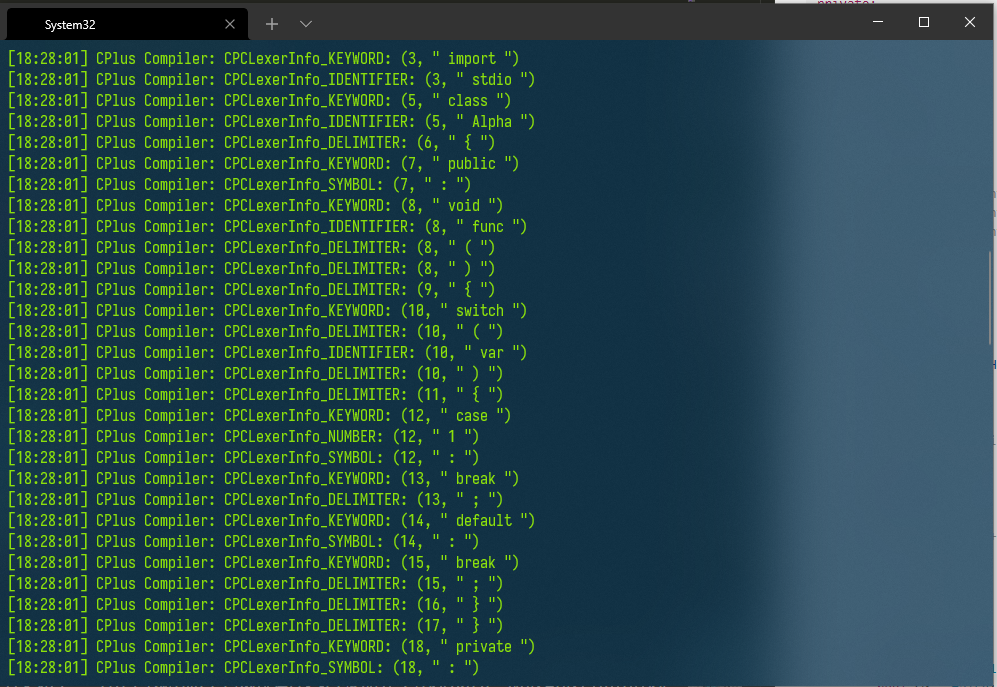
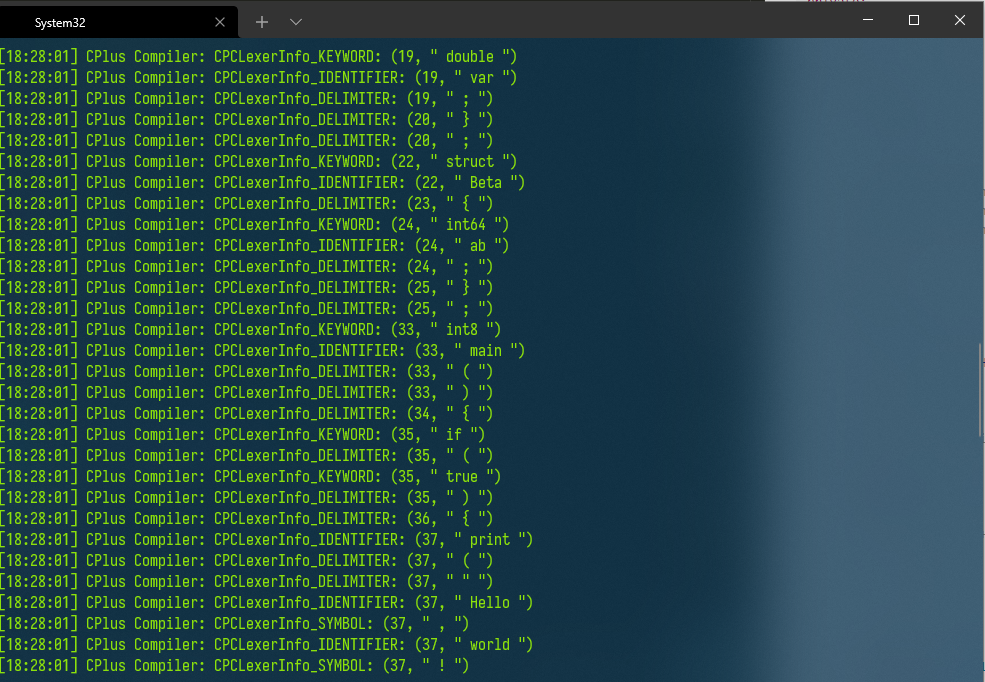
运行结果如下:(由于我将项目生成的编译器目录加入了系统path,所以可以直接由命令CPC启动)
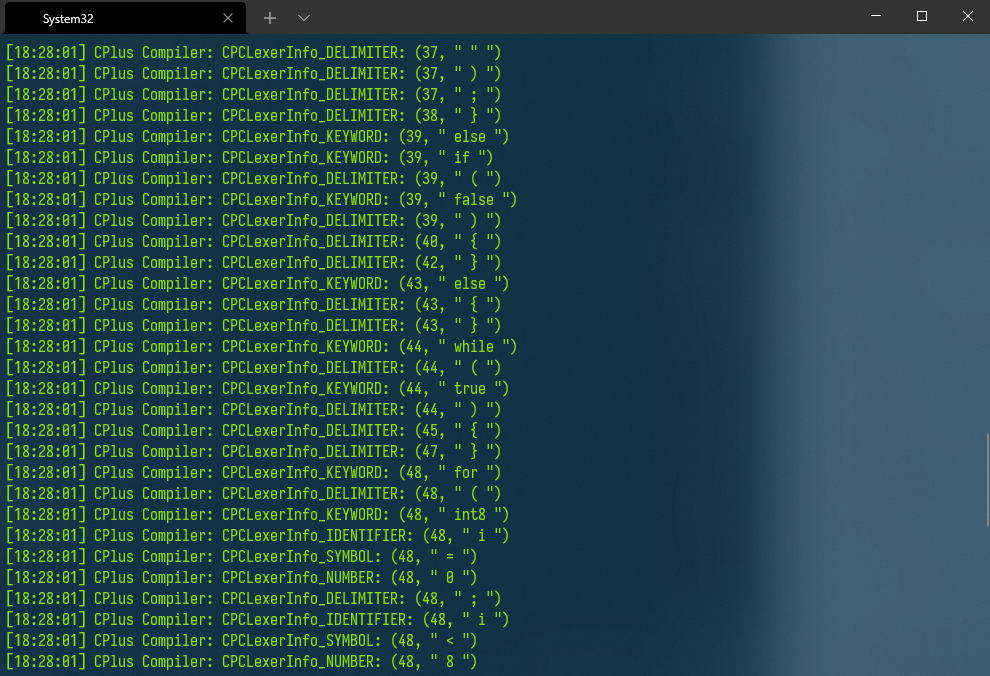
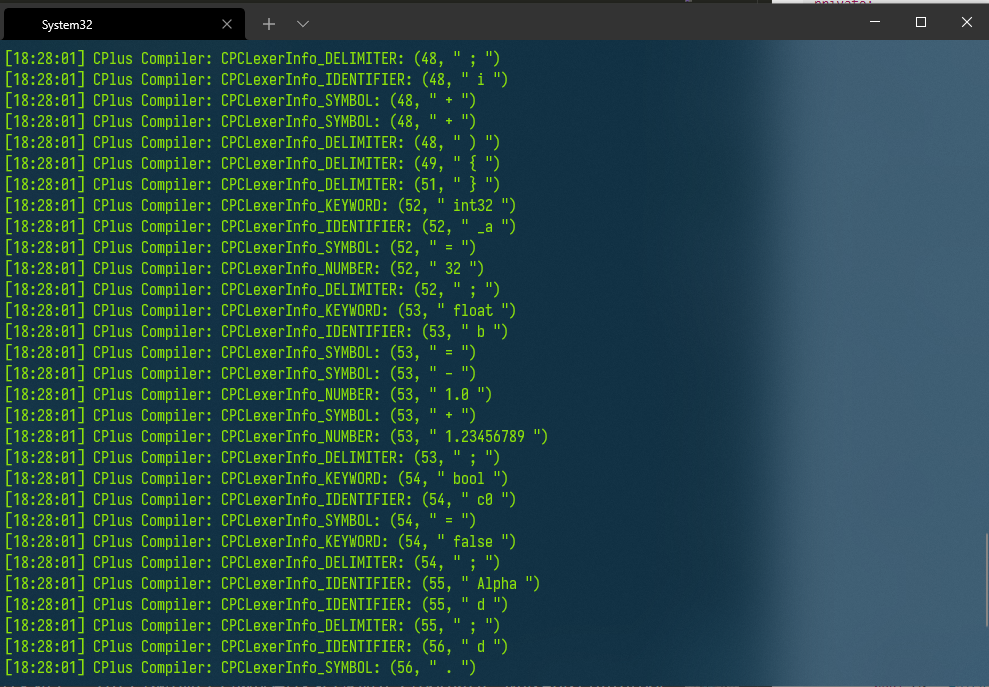
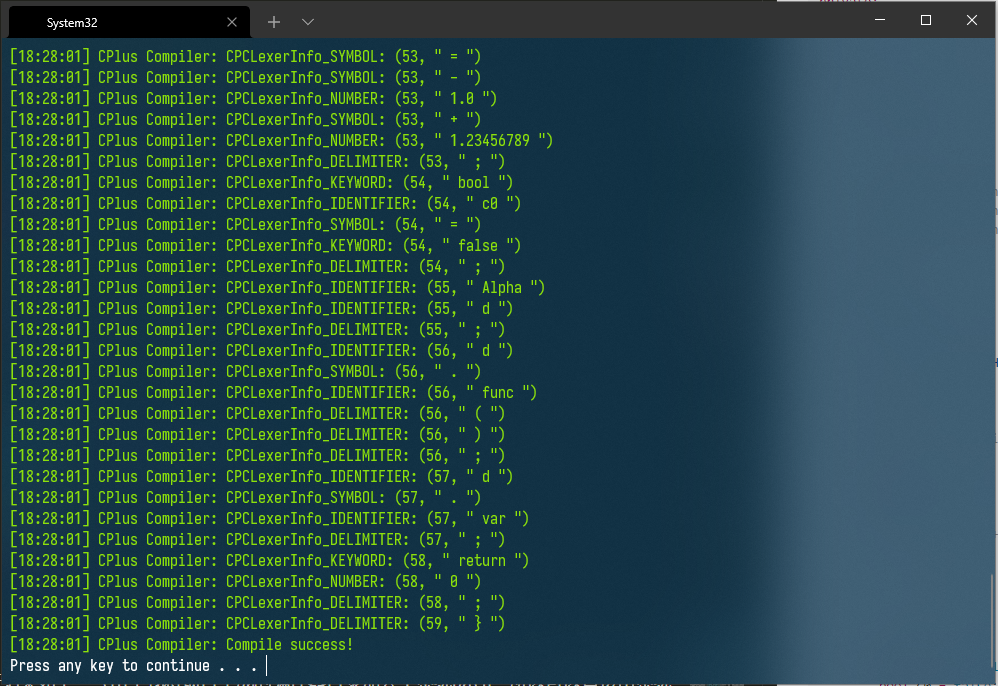
4. 结语
又是个天坑(笑),当然,我并没有忘和大家许诺的虚幻引擎系列、图形学系列以及游戏引擎系列,只是咕一会而已,并无大碍,至少不会是麻蛇和富坚老贼那样无限期拖更。额,也没什么要说的,如果有什么好的建议或者意见欢迎提出,就这样,期待下次再会!诶嘿,馕~打~油!